

Nextcloud bietet eine Vielzahl von Funktionen out-of-the-box. Noch mehr Funktionen können über Apps und externe Dienste nachgerüstet werden. Eine dieser Funktionen, ist die Volltextsuche, also die Suche nach Text, nicht nur in Dokumentennamen, sondern im Inhalt der Dokumente. Dafür reicht es aber nicht nur aus eine App zu installieren, für diese Funktion ist ein separater Dienst notwendig, z.B. Elasticsearch.
Hinweis
Eine Volltextsuche bietet auch die DiskStation an, Synology greift dabei ebenfalls auf Elasticsearch zurück. Mir ist derzeit aber nicht bekannt, dass man den vorhandenen Dienst selbst nutzen könnte, daher müssen wir, um die Volltextsuche in Nextcloud nutzen zu können, Elasticsearch selbst installieren. Dazu muss auf eurer DiskStation Docker verfügbar sein, oder ihr benötigt einen separaten (Linux-)Server auf dem Ihr Elasticsearch direkt oder via Docker bereitstellen könnt.
Achtung
Elasticsearch benötigt einiges an RAM. Auch wenn Docker zur Verfügung steht, kann, je nach dem welche Dienste sonst noch laufen und welches Modell ihr besitzt, die DiskStation schnell überfordert sein. Je nach Modell könnt ihr aber Arbeitsspeicher nachrüsten.
Elasticsearch installieren
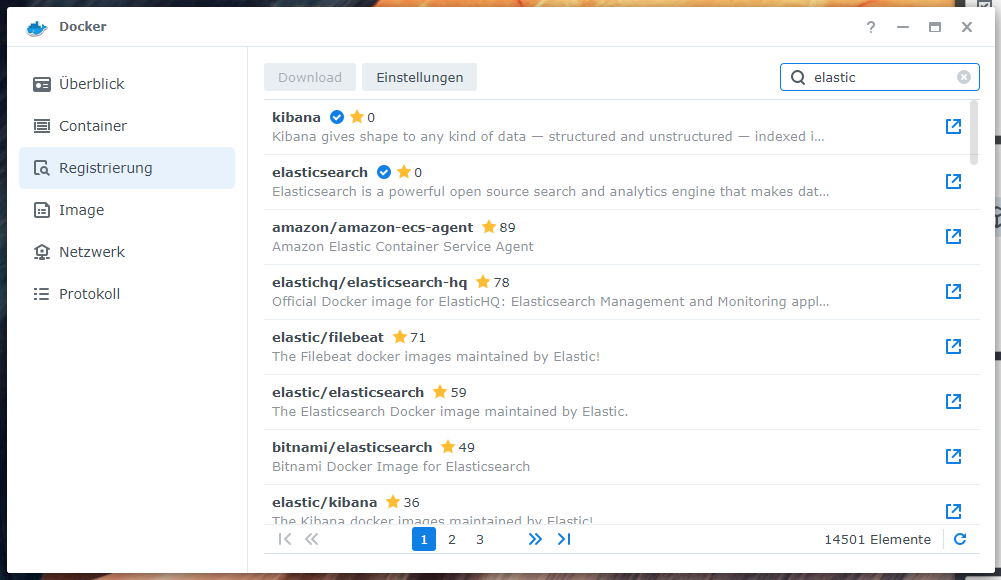
Sofern ihr Docker noch nicht auf eurer DiskStation installiert habt. Ladet das Paket aus dem Paket-Zentrum herunter und führt es aus. Öffnet Docker und wechselt in den Bereich Registrierung. Benutzt die Suchleiste um nach “elasticsearch” zu suchen. Laden dann das Image “elasticsearch” mit der Version 7.17.2 herunter.
Achtung
Es ist wichtig, die Version 7 zu verwenden, in Elasticsearch 8 wurden scheinbar einige Änderungen vorgenommen, die nicht abwärtskompatibel sind. Die aktuelle Version der Volltextsuche von Nextcloud funktioniert nur mit Version 7.
Container erstellen
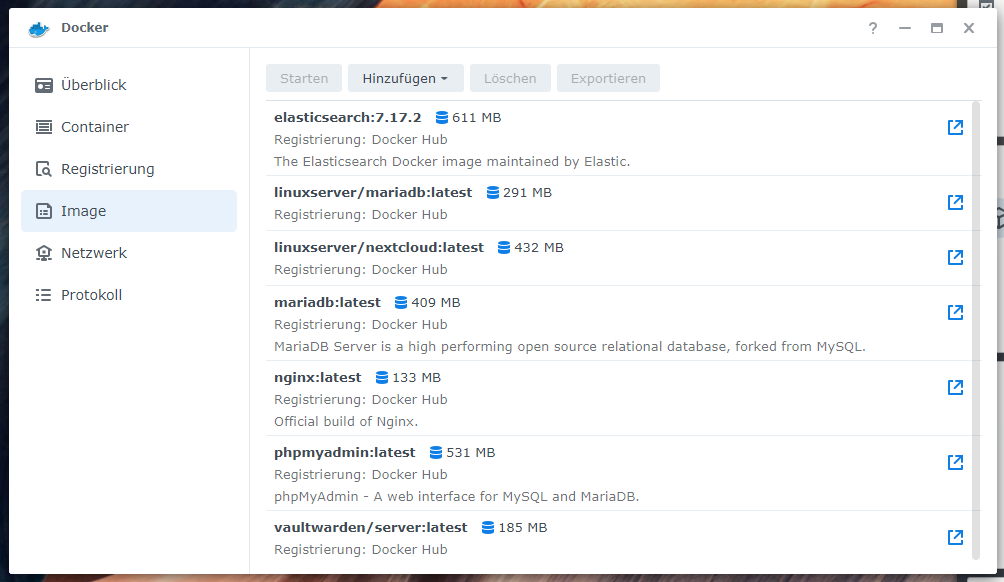
Nachdem das Image heruntergeladen wurde, wechselt in den Bereich Image. Wählt dort das Image aus und klickt auf Start (Alternative: Doppelklick auf das Image), um einen Container zu erstellen. Gebt dem Container einen Namen und klickt dann auf Erweiterte Einstellungen. Alternativ könnt ihr die Ressourcen eurer DS für den Container beschränken.
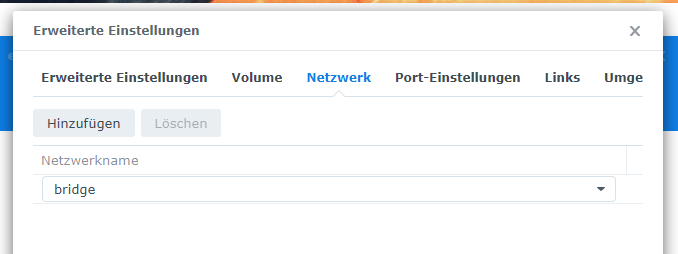
In den erweiterten Einstellungen könnt ihr im Reiter Netzwerk festlegen in welchem Netzwerkmodus der Container laufen soll – im Host-Neztwerk, im Default-Bridge-Netzwerk (vorausgewählt) oder in einem eigenen Bridge-Netzwerk. Mehr zu den Netzwerkeinstellungen könnt ihr in der Docker-Dokumentation oder in meinem Buch nachlesen. Für diese Anleitung läuft der Container im Default-Bridge-Netzwerk.
Im Reiter Port-Einstellungen findet ihr die Ports unter denen Elasticsearch erreichbar ist. Unter Lokaler Port müsst ihr “Automatisch” durch tatsächliche Ports ersetzen. Mit der Option “Automatisch” entscheidet eure DS bei jedem Start des Containers selbst welche Ports sie vergibt. Das müssen nicht immer die selben sein. Da die Ports angegeben werden müssen, wenn ihr euch mit Elasticsearch verbinden wollt, würde das so nicht funktionieren. Auch port-basierte Konfigurationen, wie etwa Firewall-Regeln würden nicht zuverlässig funktionieren. Ihr könnt die Standardports 9200 und 9300 verwenden, sonfern noch kein anderer Dienst auf eurer DS diese Ports verwendet.
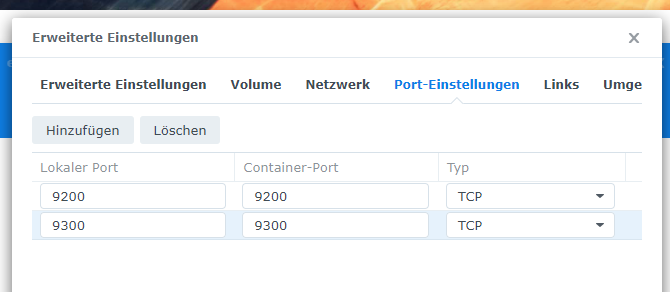
Als letztes wechselt ihr noch in den Reiter Umgebung und fügt dort eine Umgebungsvariable hinzu. Als Variablenname tragt ihr discovery.type und als Wert single-node ein.
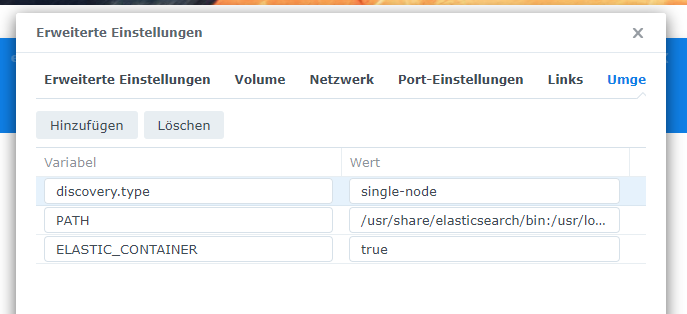
Klickt anschließend auf Übernehmen und auf Weiter. Ihr seht die Zusammenfassung der Einstellungen, vergewissert euch, dass die Option “Diesen Container nach Abschluss des Assistenten ausführen” angehakt ist und klickt auf Fertig. Der Container wird erzeugt und anschließend gestartet. Vorallem der erste Start von Elasticsearch dauert einige Zeit.
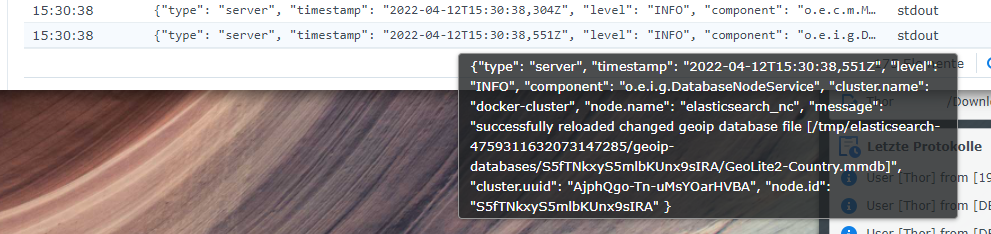
Nach einigen Minuten könnt ihr in Docker in den Bereich Container wechseln. Markiert dort den Elasticsearch-Container und klickt auf Details. In den Reitern Protokoll bzw. Terminal könnt ihr die Kommandozeilen-Ausgabe des Containers einsehen. Protokoll aktualisiert nicht automatisch, erst ein Wechsel der Reiter aktualisiert die Ausgabe. Produziert der Container keine weiteren Ausgaben mehr (in den letzten Ausgaben steht meist etwas von “reloaded geoip database file”) könnt ihr sicher gehen, dass Elasticsearch läuft.
Plugin installieren
Standardmäßig kann Elasticsearch Dokumente wie Textdateien und Office-Dokumente durchsuchen. Um PDFs zu durchsuchen, ist ein Plugin notwendig. Der Testlauf der Nextcloud-Volltextsuche schlägt fehl, wenn das Plugin nicht installiert ist. Ob die eigentliche Volltextsuche auch ohne Plugin funktioniert (ohne PDFs zu durchsuchen) habe ich nicht getestet.
Wechselt im Container-Fenster in den Reiter Terminal und klickt auf Erstellen. In der neuen Kommandozeile tippt ihr folgenden Befehle ein:
cd /bin/ elasticsearch-plugin install ingest-attachment
Bestätigt mit Enter und wartet, bis das Plugin installiert wurde. Anschließend müsst ihr Elasticsearch neustarten. Dazu könnt ihr ganz einfach den Container neustarten.

Volltextsuche in Nextcloud einrichten
Die Volltextsuche aktiviert ihr in Nextcloud über eine eigene App, bzw. über mehrere Apps. Öffnet eure Nextcloud und wechselt dort in den App-Bereich. Sucht dort die Apps “Full text search”, “Full text search – Elasticsearch Platform” und Full text search – Files” und installiert diese.
Anschließend wechselt ihr in die Einstellungen > Verwaltung > Volltextsuche. Dort wählt ihr als Suchplattform Elasticsearch aus. Im Bereich Elasticsearch tragt ihr unter “Adresse des Sevlets” http://localhost:9200 ein. Der Port 9200 bezeichnet den lokalen Port des Containers, habt ihr dort einen anderen Port verwendet, müsst ihr die URL anpassen. Unter “Index” vergebt ihr einen Namen für den Index. Der wird benötigt, falls ihr mit Elasticsearch verschiedene Dienste bedienen wollt (mehrere Nextcloud-Instanzen oder andere Dienste die Elasticsearch nutzen). Alle weiteren Einstellungen könnt ihr belassen oder nach Wahl vornehmen.
Elasticsearch testen
Jetzt ist es an der Zeit herauszufinden ob alles korrekt eingerichtet wurde. Stellt dazu eine SSH-Verbindung zu eurer DiskStation her (z.B. PuTTY). Wechselt in das Installationsverzeichnis von Nextcloud, z.B.:
cd /volume1/web/nextcloud/
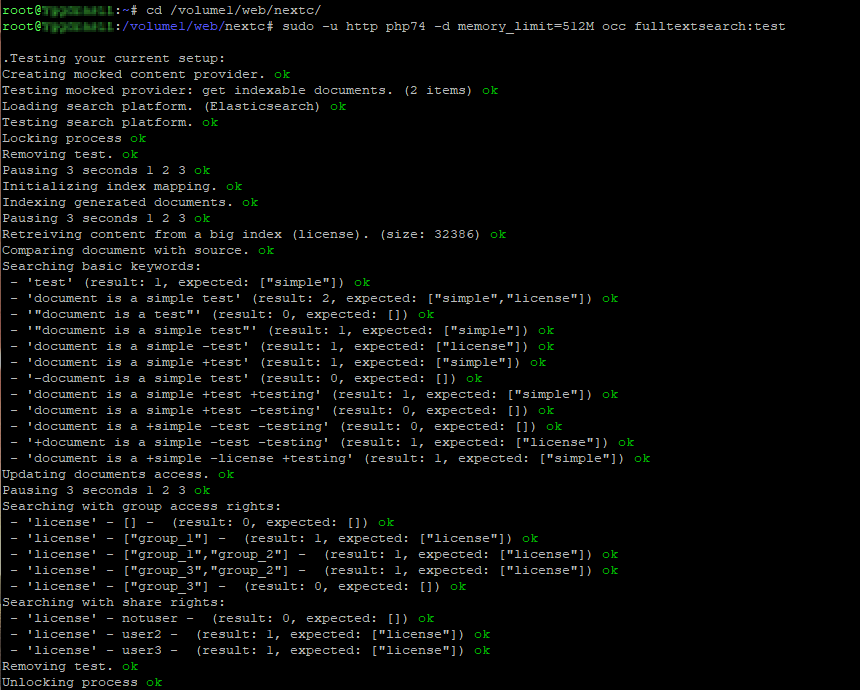
Ihr könnt die Verbindung zu Elasticsearch und die korrekte Funktion mit folgendem Befehl testen:
sudo -u http php74 -d memory_limit=512M occ fulltextsearch:test
Es startet ein Test, der einige Zeit in Anspruch nimmt.
Fehler die mir bei der Einrichtung untergekommen sind:
- no running node – Der Elasticsearch-Container läuft nicht oder ist nicht unter der angegebenen URL erreichbar. Das passiert vorallem dann, wenn die Netzwerk- und Porteinstellungen des Containers falsch sind.
illegal_argument_exceptionmitunrecognized parameter include_type_name – In diesem Fall habt ihr die falsche Version von Elasticsearch laufen.- Install ingest-attachment – Der Test schlägt fehl, wenn das Plugin nicht installiert ist. Ob ihr das ignorieren könnt und die Volltextsuche ohne PDF-Support verwenden könnt, habe ich, wie gesagt, nicht getestet.
Achtung
Der nachfolgende Abschnitt ist derzeit nicht relevant. Er dient nur als Zusatzinformation. Sollte die Volltextsuche aktualisiert werden und Elasticsearch 8 unterstützen, findet ihr hier aber einen wichtigen Hinweis, sollte ich den Artikel nicht zeitgerecht aktualisieren.
Ein weiterer Fehler, der mit ebenfalls mit der nicht unterstützten Version 8 von Elasticsearch untergekommen ist, war erst in der Ausgabe des Containers ersichtlich. Der Fehler taucht noch vor der illegal_argument_exception auf. Elasticsearch bietet verschiedene Lizenzen, die kostenpflichtige unterstützt einige Sicherheitsfunktionen wie die SSL-Verschlüsselung. Installiert ihr Elasticsearch 8 wird eine Probelizenz aktiviert bei der alle Sicherheitsfunktionen aktiviert sind. Ihr könnt dann keine HTTP-Verbindung zu Elasticsearch aufbauen. Nextcloud akzeptiert das selbst-signierte Zertifikat aber nicht und ihr könnt auch HTTPS nicht verwenden. Ihr müsst unter Details > Terminal eine neue Kommandozeile aufmachen und in der Datei /config/elasticsearch.yml die Sicherheitsfeatures auf false setzen. Theoretisch müsste es auch möglich sein einen Reverse Proxy für den Container einzurichten und diesem ein gültiges Let’s Encrypt (oder anderes) Zertifikat zuzuweisen.
Erste Indizierung vornehmen
Ist der Test erfolgreich, könnt ihr die Erstindizierung starten. Der Befehl dazu lautet:
sudo -u http php74 -d memory_limit=512M occ fulltextsearch:index
Wenn eure Nextcloud nicht gerade leer ist, dauert der Vorgang lange. Und ich meine nicht Kaffeepause-Lange. In meiner Cloud befinden sich knapp 1 TB an Daten, das meiste davon Bilder. Der Vorgang hat mehr als einen halben Tag benötigt.
Der Vorteil, die Kommandozeilenausgabe aktualisiert sich. Ihr sehr also den Fortschritt. Der Nachteil, der Vorgang wird nur durchgeführt, solange die Kommandozeile offen ist. Ihr könnt den Vorgang jederzeit abbrechen (siehe Befehlseingaben am Ende der Ausgabe, oder einfach auf die harte Tour), er lässt sich problemlos jeder Zeit fortsetzen. Es gibt dennoch ein paar Tricks, das ganze zu optimieren.
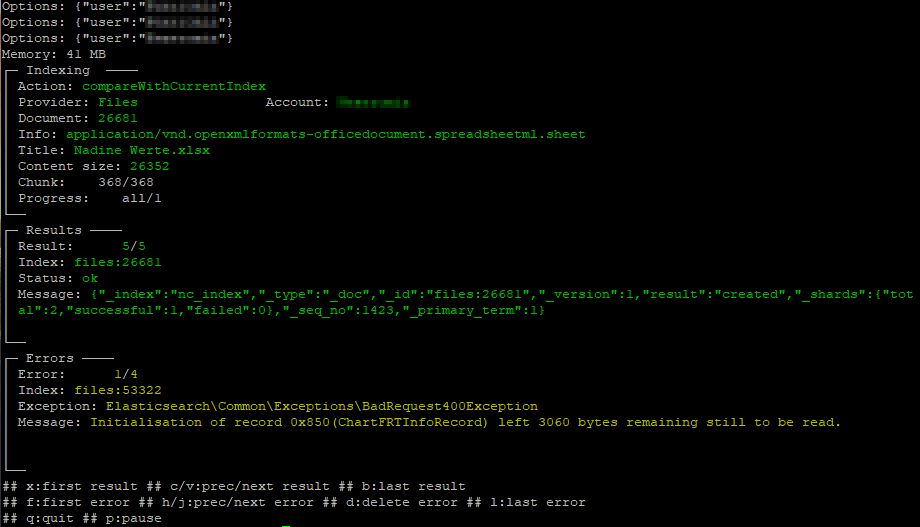
Indizierung mit Optionen steuern
Ihr könnt der Indizierung Optionen im JSON-Format mitgeben. Unter anderem könnt ihr einen Nextcloud-Benutzer und einen Pfad angeben. Ihr könnt die Indizierung also auf einen Benutzer oder sogar einen Ordner beschränken. Das Format sieht so aus: "[\"user\":\"<Name>\"}” bzw. mit Pfad: "[\"user\":\"<Name>\", \"path\":\"<Pfad>\"}"
Es gibt noch weitere Parameter, die könnt ihr in der Dokumentation der App nachlesen.
Indizierung im Hintergrund ausführen
Damit euer Rechner nicht die ganze Zeit laufen muss, könnt ihr die Indizierung auch direkt über eure DiskStation anstoßen. Öffnet dazu den Aufgabenplaner und erstellt eine geplante Aufgabe > benutzerdefiniertes Skript.
Vergebt einen Namen und wählt als Benutzer “root”. Der Zeitplan ist egal. Unter “Aufgabeneinstellungen” lasst ihr euch per Mail benachrichtigen und fügt folgende Zeilen ein:
cd /volume1/web/nextcloud/ sudo -u http php74 -d memory_limit=512M occ fulltextsearch:index <Eventuell Optionen>
Deaktiviert die Aufgabe, damit Sie nicht zeitgesteuert ausgeführt wird und führt sie dann manuell aus. Schlägt sie fehl, wird sie abgebrochen oder ist sie erfolgreich, erhaltet ihr eine Mail mit der Ausgabe auf der Kommandozeile.
Volltextsuche verwenden
Ist die Indizierung abgeschlossen, könnt ihr die Volltextsuche in Nextcloud verwenden. Dabei wird das vorhandene Suchfeld durch die App “Full text search – Files” durch die Volltextsuche erweitert. Zusätzlich zu Ordner und Dateinamen, werden jetzt auch die Inhalte der Dokumente durchsucht.
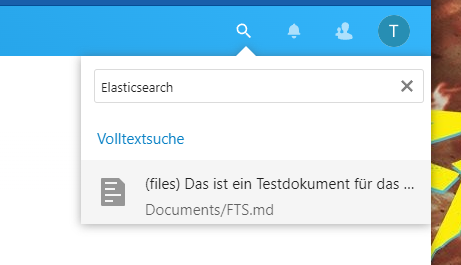
Ist die initiale Indizierung abgeschlossen, müsst ihr den Index-Befehl übrigens nicht regelmäßig ausführen. Die Indizierung neuer Inhalte übernimmt der Nextcloud-Cron für euch.
Plugins müsst ihr übrigens selbst aktualisieren. Solange ihr Elasticsearch nicht aktualisiert sollte es aber keine Probleme geben, wenn ihr das nicht tut. Um ein Plugin zu aktualisieren, entfernt ihr es mit remove und installiert es dann wieder neu.

Möchtet Ihr noch detailliertere Schritt-Für-Schritt-Anleitungen für euer Synology NAS, mit viel mehr Hintergrundinformationen, Tipps und Tricks? Dann holt euch mein Wissen als als umfassendes Praxis-Handbuch. Mehr Infos findet ihr in keinem Buch zu Synology und alles in der von mir gewohnten Qualität.
Die dritte Auflage enthält Aktualisierungen zu DSM 7.1 und den Updates von WebStation, Surveillance Station und Synology Photos.
Das Buch direkt beim Verlag
Das Buch auf Amazon

Hallo Andreas,
vielen Dank für die Anleitung. Bei mir scheitert es schon damit, den Container laufen zu lassen. Es gibt einige ungute Meldungen im Protokoll, mir fallen vor allem auf:
2024/01/14 11:16:10 stdout “stacktrace”: [“java.lang.UnsupportedOperationException: seccomp unavailable: CONFIG_SECCOMP not compiled into kernel, CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER are needed”,
2024/01/14 11:16:10 stdout {“type”: “server”, “timestamp”: “2024-01-14T10:16:10,977Z”, “level”: “WARN”, “component”: “o.e.b.JNANatives”, “cluster.name”: “docker-cluster”, “node.name”: “elasticsearch”, “message”: “unable to install syscall filter: “,
Versucht habe ich es mit Elasticserach 7.17.2 und 7.17.16
DSM Version ist DSM 7.2.1-69057 Update 3 auf Synology DS 224+
Vielleicht sagt dir das ja was und du hast einen Tipp.
Viele Grüße
Jens
Danke für die Anleitung. Doch leider ist der Befehl elasticsearch-plugin bei mir nicht im Container vorhanden?! Woran könnte das liegen?
Hallo,
Ich hab den Container derzeit nicht in Verwendung da ich Probleme an anderer stelle hatte. Was mit generell mit Containern aufgefallen ist, je nach Version werden oft Befehle geändert. Bzw. sind Befehle manchmal in anderer Form verfügbar.
Schau dir am besten die elasticsearch Dokumentation an. Bzw. such dir ein Tutorial zu elasticsearch und Plugins. Der Teil ist unabhängig von Synology und es sollte dazu Infos im Web geben.
Grüße
Andreas
Vielen Dank für die hilfreichen Anleitungen auf der Seite! Gerade die Volltextsuche fände ich für mich sehr spannend. Leider kommt bei mir allerdings sowohl beim Test als auch bei der Erstindizierung im Aufgabenplaner der Synology die Fehlermeldung „Could not open input file: occ“. Woran könnte das liegen? Danke!
Hallo Elias,
OCC ist ein Programm das sich im Nextcloud-Verzeichnis befindet, die DiskStation kennt das Programm nicht, daher musst du vor der Ausführung des Befehls in das Nextcloud-Installationsverzeichnis unter /web wechseln.
Grüße,
Andreas